Newly shared Microsoft DP-100 exam learning preparation program! Get the latest DP-100 exam exercise questions and exam dumps pdf for free! 100% pass the exam to select
the full Microsoft DP-100 dumps: https://www.leads4pass.com/dp-100.html the link to get VCE or PDF. All exam questions are updated!
leads4pass offers the latest Microsoft DP-100 PDF
[Latest updates] Free Microsoft DP-100 dumps pdf download from leads4pass: https://drive.google.com/file/d/1NovY2_qRyL406H_fpDWAReabC7PV-iQh/
latest updated Microsoft DP-100 exam questions and answers
QUESTION 1
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are using Azure Machine Learning Studio to perform feature engineering on a dataset.
You need to normalize values to produce a feature column grouped into bins.
Solution: Apply an Entropy Minimum Description Length (MDL) binning mode.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: A
Entropy MDL binning mode: This method requires that you select the column you want to predict and the column or
columns that you want to group into bins. It then makes a pass over the data and attempts to determine the number of bins that minimizes the entropy. In other words, it chooses a number of bins that allows the data column to best predict the target column. It then returns the bin number associated with each row of your data in a column named quantized.
References: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/group-data-into-bins
QUESTION 2
HOTSPOT
You have a dataset that includes home sales data for a city. The dataset includes the following columns.
Each row in the dataset corresponds to an individual home sales transaction.
You need to use automated machine learning to generate the best model for predicting the sales price based on the
features of the house.
Which values should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
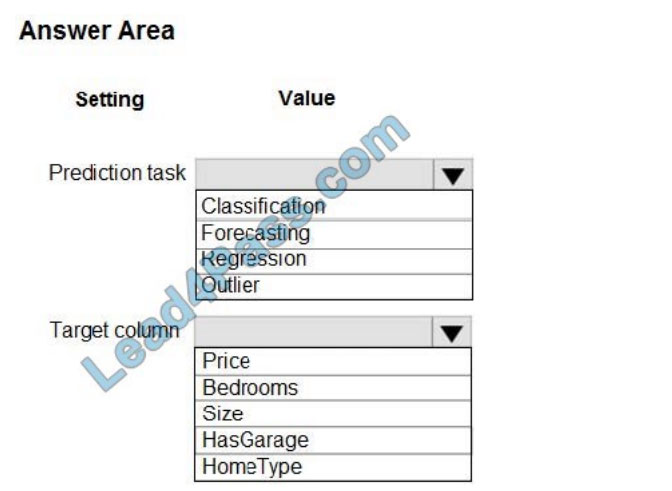
Correct Answer:

Box 1: Regression
Regression is a supervised machine learning technique used to predict numeric values.
Box 2: Price
Reference:
https://docs.microsoft.com/en-us/learn/modules/create-regression-model-azure-machine-learning-designer
QUESTION 3
You create a multi-class image classification deep learning model that uses the PyTorch deep learning framework.
You must configure Azure Machine Learning Hyperdrive to optimize the hyperparameters for the classification model.
You need to define a primary metric to determine the hyperparameter values that result in the model with the best
accuracy score.
Which three actions must you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
A. Set the primary_metric_goal of the estimator used to run the bird_classifier_train.py script to maximize.
B. Add code to the bird_classifier_train.py script to calculate the validation loss of the model and log it as a float value
with the key loss.
C. Set the primary_metric_goal of the estimator used to run the bird_classifier_train.py script to minimize.
D. Set the primary_metric_name of the estimator used to run the bird_classifier_train.py script to accuracy.
E. Set the primary_metric_name of the estimator used to run the bird_classifier_train.py script to loss.
F. Add code to the bird_classifier_train.py script to calculate the validation accuracy of the model and log it as a float
value with the key accuracy.
Correct Answer: ADF
AD:
primary_metric_name=”accuracy”,
primary_metric_goal=PrimaryMetricGoal.MAXIMIZE
Optimize the runs to maximize “accuracy”. Make sure to log this value in your training script.
Note:
primary_metric_name: The name of the primary metric to optimize. The name of the primary metric needs to exactly
match the name of the metric logged by the training script. primary_metric_goal: It can be either
PrimaryMetricGoal.MAXIMIZE or PrimaryMetricGoal.MINIMIZE and determines whether the primary metric will be
maximized or minimized when evaluating the runs.
F: The training script calculates the val_accuracy and logs it as “accuracy”, which is used as the primary metric.
QUESTION 4
HOTSPOT
You have a dataset that contains 2,000 rows. You are building a machine learning classification model by using Azure
Learning Studio. You add a Partition and Sample module to the experiment.
You need to configure the module. You must meet the following requirements:
1. Divide the data into subsets
2. Assign the rows into folds using a round-robin method
3. Allow rows in the dataset to be reused
How should you configure the module? To answer, select the appropriate options in the dialog box in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Correct Answer:

Use the Split data into partitions option when you want to divide the dataset into subsets of the data. This option is also useful when you want to create a custom number of folds for cross-validation, or to split rows into several groups.
Add the Partition and Sample module to your experiment in Studio (classic), and connect the dataset.
For Partition or sample mode, select Assign to Folds.
Use replacement in the partitioning: Select this option if you want the sampled row to be put back into the pool of rows for potential reuse. As a result, the same row might be assigned to several folds.
If you do not use replacement (the default option), the sampled row is not put back into the pool of rows for potential
reuse. As a result, each row can be assigned to only one fold.
Randomized split: Select this option if you want rows to be randomly assigned to folds.
If you do not select this option, rows are assigned to folds using the round-robin method.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
QUESTION 5
HOTSPOT
You create a binary classification model using Azure Machine Learning Studio.
You must use a Receiver Operating Characteristic (RO C) curve and an F1 score to evaluate the model.
You need to create the required business metrics.
How should you complete the experiment? To answer, select the appropriate options in the dialog box in the answer
area; NOTE: Each correct selection is worth one point. 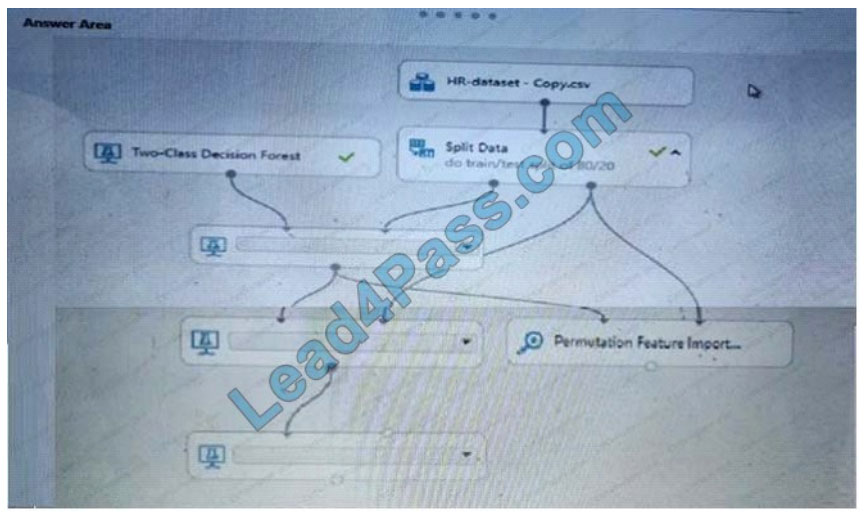
Hot Area:
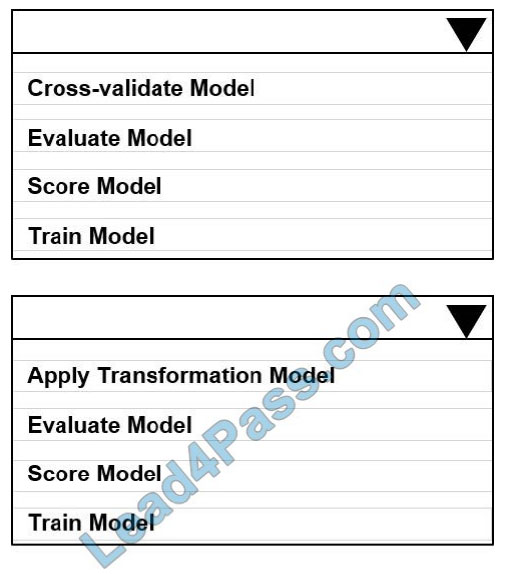

Correct Answer:
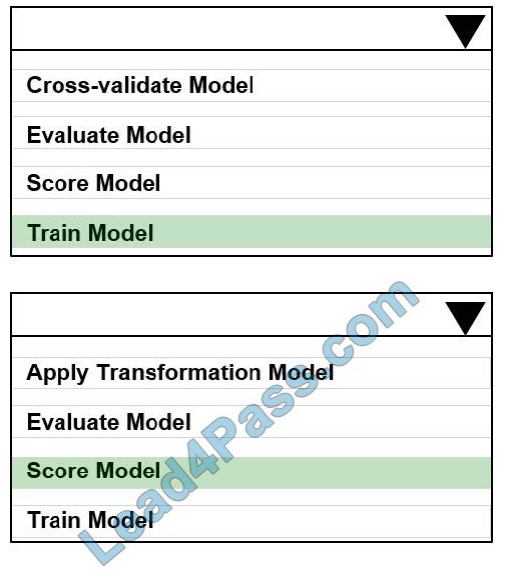

QUESTION 6
HOTSPOT
You have an Azure blob container that contains a set of TSV files. The Azure blob container is registered as a datastore
for an Azure Machine Learning service workspace. Each TSV file uses the same data schema.
You plan to aggregate data for all of the TSV files together and then register the aggregated data as a dataset in an
Azure Machine Learning workspace by using the Azure Machine Learning SDK for Python.
You run the following code. 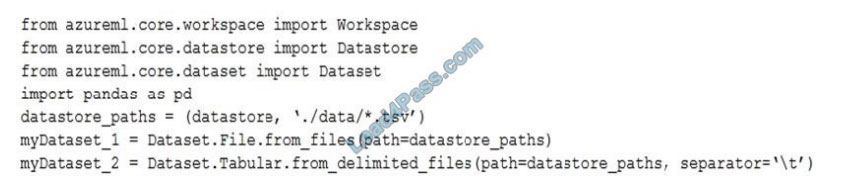
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: No
FileDataset references single or multiple files in datastores or from public URLs. The TSV files need to be parsed.
Box 2: Yes
to_path() gets a list of file paths for each file stream defined by the dataset.
Box 3: Yes
TabularDataset.to_pandas_dataframe loads all records from the dataset into a pandas DataFrame.
TabularDataset represents data in a tabular format created by parsing the provided file or list of files.
Note: TSV is a file extension for a tab-delimited file used with spreadsheet software. TSV stands for Tab Separated
Values. TSV files are used for raw data and can be imported into and exported from spreadsheet software. TSV files
are essentially text files, and the raw data can be viewed by text editors, though they are often used when moving raw data between spreadsheets.
Reference:
https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.data.tabulardataset
QUESTION 7
You need to visually identify whether outliers exist in the Age column and quantify the outliers before the outliers are
removed. Which three Azure Machine Learning Studio modules should you use? Each correct answer presents part of
the solution. NOTE: Each correct selection is worth one point.
A. Create Scatterplot
B. Summarize Data
C. Clip Values
D. Replace Discrete Values
E. Build Counting Transform
Correct Answer: ABC
B: To have a global view, the summarize data module can be used. Add the module and connect it to the data set that
needs to be visualized.
A: One way to quickly identify Outliers visually is to create scatter plots.
C: The easiest way to treat the outliers in Azure ML is to use the Clip Values module. It can identify and optionally
replace data values that are above or below a specified threshold.
You can use the Clip Values module in Azure Machine Learning Studio, to identify and optionally replace data values
that are above or below a specified threshold. This is useful when you want to remove outliers or replace them with a
mean, a constant, or other substitute value.
References: https://blogs.msdn.microsoft.com/azuredev/2017/05/27/data-cleansing-tools-in-azure-machine-learning/
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clip-values Question Set 3
QUESTION 8
You are creating a classification model for a banking company to identify possible instances of credit card fraud. You
plan to create the model in Azure Machine Learning by using automated machine learning.
The training dataset that you are using is highly unbalanced.
You need to evaluate the classification model.
Which primary metric should you use?
A. normalized_mean_absolute_error
B. AUC_weighted
C. accuracy
D. normalized_root_mean_squared_error
E. spearman_correlation
Correct Answer: B
AUC_weighted is a Classification metric.
Note: AUC is the Area under the Receiver Operating Characteristic Curve. Weighted is the arithmetic mean of the score
for each class, weighted by the number of true instances in each class.
Incorrect Answers:
A: normalized_mean_absolute_error is a regression metric, not a classification metric.
C: When comparing approaches to imbalanced classification problems, consider using metrics beyond accuracy such
as recall, precision, and AUROC. It may be that switching the metric you optimize for during parameter selection or
model selection is enough to provide desirable performance detecting the minority class.
D: normalized_root_mean_squared_error is a regression metric, not a classification metric.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-understand-automated-ml
QUESTION 9
HOTSPOT
You are using the Hyperdrive feature in Azure Machine Learning to train a model.
You configure the Hyperdrive experiment by running the following code:
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.
Hot Area:

Correct Answer:

Box 1: Yes
In random sampling, hyperparameter values are randomly selected from the defined search space. Random sampling
allows the search space to include both discrete and continuous hyperparameters.
Box 2: Yes
learning_rate has a normal distribution with mean value 10 and a standard deviation of 3.
Box 3: No
keep_probability has a uniform distribution with a minimum value of 0.05 and a maximum value of 0.1.
Box 4: No
number_of_hidden_layers takes on one of the values [3, 4, 5].
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-tune-hyperparameters
QUESTION 10
You use the following code to run a script as an experiment in Azure Machine Learning:
You must identify the output files that are generated by the experiment run.
You need to add code to retrieve the output file names.
Which code segment should you add to the script?
A. files = run.get_properties()
B. files= run.get_file_names()
C. files = run.get_details_with_logs()
D. files = run.get_metrics()
E. files = run.get_details()
Correct Answer: B
You can list all of the files that are associated with this run record by called run.get_file_names()
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-track-experiments
QUESTION 11
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains
a unique solution that might meet the stated goals. Some question sets might have more than one correct solution,
while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not
appear in the review screen.
You are creating a new experiment in Azure Machine Learning Studio.
One class has a much smaller number of observations than the other classes in the training set.
You need to select an appropriate data sampling strategy to compensate for the class imbalance.
Solution: You use the Stratified split for the sampling mode.
Does the solution meet the goal?
A. Yes
B. No
Correct Answer: B
Instead use the Synthetic Minority Oversampling Technique (SMOTE) sampling mode.
Note: SMOTE is used to increase the number of underepresented cases in a dataset used for machine learning.
SMOTE is a better way of increasing the number of rare cases than simply duplicating existing cases.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/smote
QUESTION 12
HOTSPOT
You need to identify the methods for dividing the data according to the testing requirements.
Which properties should you select? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
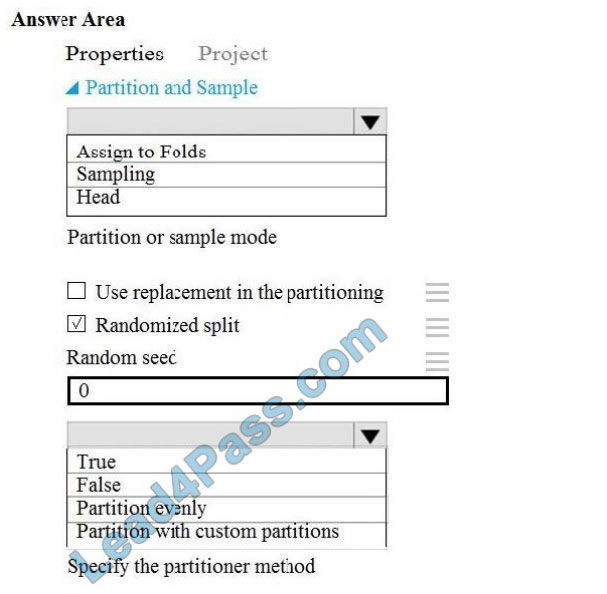
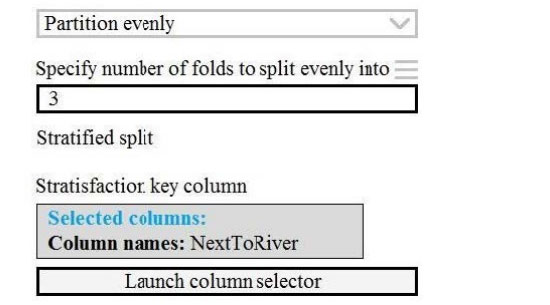
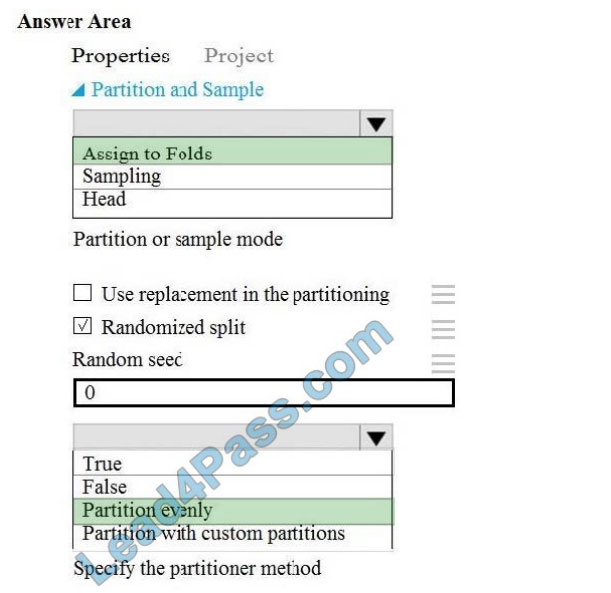
Correct Answer:
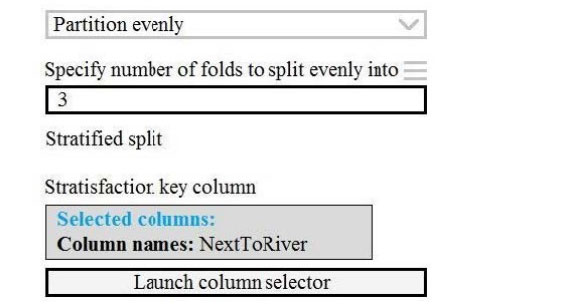
Scenario: Testing
You must produce multiple partitions of a dataset based on sampling using the Partition and Sample module in Azure
Machine Learning Studio.
Box 1: Assign to folds
Use Assign to folds option when you want to divide the dataset into subsets of the data. This option is also useful when you want to create a custom number of folds for cross-validation, or to split rows into several groups.
Not Head: Use Head mode to get only the first n rows. This option is useful if you want to test a pipeline on a small
number of rows, and don\\’t need the data to be balanced or sampled in any way.
Not Sampling: The Sampling option supports simple random sampling or stratified random sampling. This is useful if
you want to create a smaller representative sample dataset for testing.
Box 2: Partition evenly
Specify the partitioner method: Indicate how you want data to be apportioned to each partition, using these options:
Partition evenly: Use this option to place an equal number of rows in each partition. To specify the number of output
partitions, type a whole number in the Specify number of folds to split evenly into text box.
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/algorithm-module-reference/partition-and-sample
QUESTION 13
DRAG DROP
An organization uses Azure Machine Learning service and wants to expand their use of machine learning.
You have the following compute environments. The organization does not want to create another compute
environment.

You need to determine which compute environment to use for the following scenarios.
Which compute types should you use? To answer, drag the appropriate compute environments to the correct scenarios.
Each compute environment may be used once, more than once, or not at all. You may need to drag the split bar
between
panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place:

Correct Answer:

Box 1: nb_server Box 2: mlc_cluster With Azure Machine Learning, you can train your model on a variety of resources
or environments, collectively referred to as compute targets. A compute target can be a local machine or a cloud
resource, such as an Azure Machine Learning Compute, Azure HDInsight or a remote virtual machine.
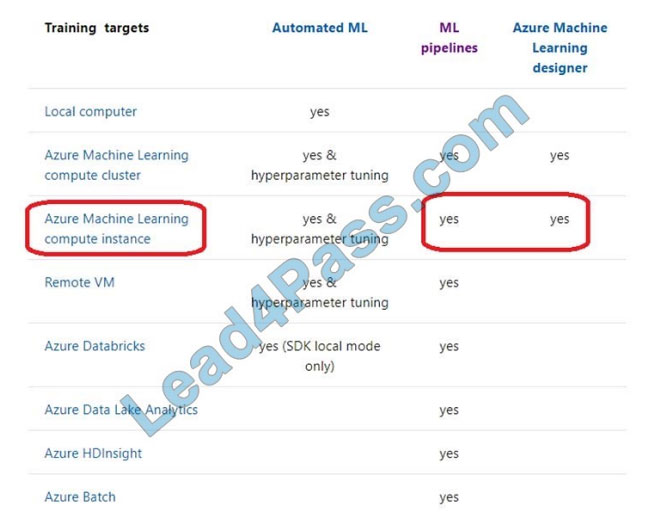
Reference:
https://docs.microsoft.com/en-us/azure/machine-learning/concept-compute-target
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-set-up-training-targets
QUESTION 14
You create a new Azure subscription. No resources are provisioned in the subscription.
You need to create an Azure Machine Learning workspace.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Run Python code that uses the Azure ML SDK library and calls the Workspace.create method with name,
subscription_id, resource_group, and location parameters.
B. Use an Azure Resource Management template that includes a Microsoft.MachineLearningServices/ workspaces
resource and its dependencies.
C. Use the Azure Command Line Interface (CLI) with the Azure Machine Learning extension to call the az group create
function with –name and –location parameters, and then the az ml workspace create function, specifying ? and
Correct Answer: BCD
B: You can use an Azure Resource Manager template to create a workspace for Azure Machine Learning.
Example:
{“type”: “Microsoft.MachineLearningServices/workspaces”, …
C: You can create a workspace for Azure Machine Learning with Azure CLI Install the machine learning extension.
Create a resource group: az group create –name –location
To create a new workspace where the services are automatically created, use the following command: az ml workspace
create -w -g
D: You can create and manage Azure Machine Learning workspaces in the Azure portal.
1. Sign in to the Azure portal by using the credentials for your Azure subscription.
2. In the upper-left corner of Azure portal, select + Create a resource.
3. Use the search bar to find Machine Learning.
4. Select Machine Learning.
5. In the Machine Learning pane, select Create to begin.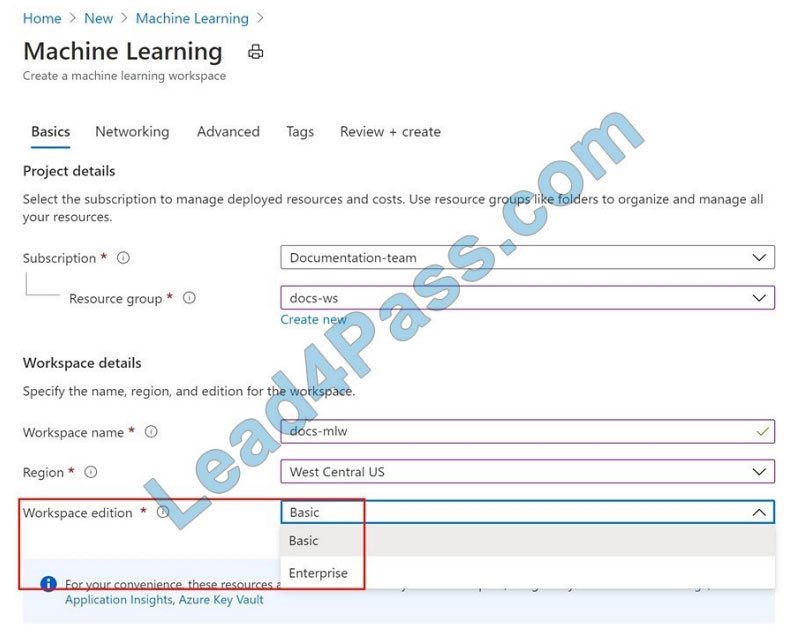
Reference: https://docs.microsoft.com/en-us/azure/machine-learning/how-to-create-workspace-template
https://docs.microsoft.com/en-us/azure/machine-learning/how-to-manage-workspace-cli https://docs.microsoft.com/enus/azure/machine-learning/how-to-manage-workspace
QUESTION 15
You create an Azure Machine Learning compute resource to train models. The compute resource is configured as
follows:
1. Minimum nodes: 2
2. Maximum nodes: 4
You must decrease the minimum number of nodes and increase the maximum number of nodes to the following values:
1. Minimum nodes: 0
2. Maximum nodes: 8
You need to reconfigure the compute resource.
What are three possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
A. Use the Azure Machine Learning studio.
B. Run the update method of the AmlCompute class in the Python SDK.
C. Use the Azure portal.
D. Use the Azure Machine Learning designer.
E. Run the refresh_state() method of the BatchCompute class in the Python SDK.
Correct Answer: ABC
A: You can manage assets and resources in the Azure Machine Learning studio.
B: The update(min_nodes=None, max_nodes=None, idle_seconds_before_scaledown=None) of the AmlCompute class
updates the ScaleSettings for this AmlCompute target.
C: To change the nodes in the cluster, use the UI for your cluster in the Azure portal.
Reference: https://docs.microsoft.com/en-us/python/api/azureml-core/azureml.core.compute.amlcompute(class)
Summarize:
Buklsainsa free to share Microsoft DP-100 exam exercise questions, DP-100 pdf, DP-100 exam video! leads4pass updated exam questions and answers throughout the year!
Make sure you pass the exam successfully. Select lead4Pass DP-100 to pass the Microsoft DP-100 exam “Designing and Implementing a Data Science Solution on Azure“.
ps. Latest update leads4pass DP-100 dumps: https://www.leads4pass.com/dp-100.html (235 Q&As)
[Latest updates] Free Microsoft DP-100 Dumps pdf download from Google Drive: https://drive.google.com/file/d/1NovY2_qRyL406H_fpDWAReabC7PV-iQh/

